
When I’ve learned about data engineering and started to setup our own system first I was in trouble how to do that the best way. How the architecture should look like for our exact needs? Those questions were even harder after having some consultations with other experts and completing more and more training materials. Ultimately the question that we should answer was kind of the following: Do we need a “Data Ferrari” or a “Data Toyota”?
Imaging you are looking for a car and you are not Elon Musk or an Arab sheikh. What is the important things for your car? Definitely speed is on Ferrari’s plate, Toyota cannot compete with that. However if you choose Toyota, probably you cannot wait weeks or months for your car, and more importantly you shouldn’t pay million dollars not only for the car, but also for it’s further maintenance. Even Ferrary should bring you faster, your ultimate purpose to get from A to B, would be fulfilled with both options.
That’s the concept I’ve incorporated in my data architecture. My goals was to create an environment which incorporates all data warehousing and ELT best practices excluding the ones which would need huge amount of time to develop. Our corporate function that time was engineering all data tables one-by-one. They even separated data tables to a Fact and Dim based on if the data is fast changing or constant. And here I’m not talking about having Fact and Dim tables, but having e.g. a Sales Orders table and separating it to have the Amount or Quantity type of fields in the Sales Orders Fact and the Name and Category type of fields in the Sales Order Dim table. This approach is extremely resource intensive and takes a long time to develop. Also any change request is a stand-alone project.
My approach was to create sustainable data pipelines which can be easily scaled and they are kind of self-sustaining themselves. I created them to keep the format of the original data source – it is actually still more familiar for users as well, but to apply all of the data warehousing best practices possible
In this approach all the work is configured and managed through control tables. Those control tables contains some essential information about what are the objects to be ingested from the data source:

TableName contains the object which should be ingested. NeedSCD2 defines if we need to historize data. RefreshFrequency also can be set. Type is defining if the object is a Dim or Fact table.
This kind of control table can be maintained very easily with a single SQL script:
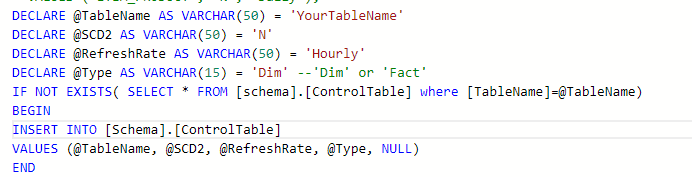
Then the Pipeline itself is created with parameters and is doing the all necessary transformation steps for each tables we would ingest from the source:

It processes the following actions:
- Lookup the current timestamp
- Lookup all tables from the Control Table to be processed
- Apply the following to each:
- Check whether the table is already existing or not
- If doesn’t exist it created with the proper table distribution and indexing based on the characteristics of the table
- It pulls the primary keys of the table from the source
- It applies an incremental data load based on last modification date
- It dynamically check and adjust schema changes in the table
- Handles hard deleted items
- Updates/Creates statistics on tables
- Creates timestamp to know when the pipeline was run
However testing this approach show that this approach is somewhat worse by performance than a perfectly engineered DWH schema, and it also causes a slightly higher cost in capacity needs, the development and maintenance time is way-way lower. With that we can deliver project extremely quickly without additional human resources and the maintenance also requires very small amount of time.
Industry standard? No. Working well? Yes.
Happy to hear your thoughts and experience.
One response to “The “Data Ferrari” vs “Data Toyota””
-
[…] introduced in my other article I’m setting up dynamic pipelines to create sustainable and scalable flow for data integration. […]
LikeLike


Leave a comment